
What is an IT Disaster Recovery Checklist?
An IT disaster recovery checklist is a guide that outlines the key steps and procedures for a company while recovering critical systems and data in the event of a disaster caused by cyberattacks, natural calamities, or even system failures. The key purpose of a recovery checklist is to minimize data loss, downtime, and business disruption by providing a clear, step-by-step recovery plan.
The checklist helps teams act swiftly and consistently in the face of disaster, reducing panic and enabling a smoother return to normal operations. It typically includes steps such as asset and data backup verification, risk assessment, recovery team roles, communication plans, and system restoration procedures. Additionally, it also outlines post-recovery evaluations and testing schedules to improve disaster readiness.
Why Is a Disaster Recovery Checklist Important?
A disaster recovery checklist is crucial for businesses to maintain durability and strength, as without a reliable DR plan, companies risk prolonged downtime, financial setbacks, data loss, and damage to reputation.
Here are some importance of a disaster recovery checklist:
- Ensures business continuity by providing a structured plan to efficiently recover critical systems, ensuring the business can continue operations with minimal disruptions.
- Reduces downtime and data loss by outlining recovery steps that help IT teams respond faster. This reduces the risk of data loss and prolonged outages.
- Clarifies team responsibilities to avoid confusion during emergencies and ensure each task is handled by the right person.
- Improves communication with internal and external communication plans that keep stakeholders informed throughout the recovery process.
- Supports regulatory compliance by helping companies meet legal and audit requirements.
- Promotes regular testing and updates, helping identify gaps and update procedures based on new risks or system changes.
- Builds confidence among stakeholders by providing reassurance to employees, partners, and customers with a recovery plan for emergencies.
What Are The Core Components of a Disaster Recovery Checklist?
The core components of a disaster recovery checklist are risk assessment, critical assets inventory, recovery objectives, backup procedures, communication plan, disaster recovery procedures, and business impact analysis. This dynamic approach strengthens a company’s durability and readiness for future disruptions.
Risk Assessment and Business Impact Analysis (BIA)
Before you can recover from a disaster, you must understand what you’re up against and what’s at stake. Risk assessment evaluates the threats your organization may face, from cyberattacks to hardware failures, while Business Impact Analysis (BIA) quantifies the fallout these events could have on operations, finances, and regulatory compliance. Together, these two activities form the strategic core of disaster planning, ensuring recovery efforts are prioritized where they matter most.
- Identify internal and external threats (cyberattacks, power loss, user error).
- Assess the likelihood and frequency of each risk type.
- Determine which business processes are most critical.
- Estimate downtime tolerance and financial impact per disruption.
- Use findings to prioritize system protections and recovery timelines.
Recovery Objectives
In every disaster scenario, time and data are your most limited resources. Recovery objectives define the acceptable limits of downtime and data loss, using RTO (Recovery Time Objective) and RPO (Recovery Point Objective), so that systems can be prioritized based on operational impact. These benchmarks help shape the architecture of backups, infrastructure investments, and overall response strategies.
- Define RTO for each critical system and application.
- Establish RPO to set acceptable data loss thresholds.
- Use RTO/RPO to shape backup frequency and architecture.
- Link recovery objectives to SLAs and business priorities.
- Reassess objectives during quarterly risk reviews.
Team Roles and Responsibilities
A well-defined disaster recovery team is the difference between chaos and control. Assigning specific roles ensures every technical task, communication effort, and approval checkpoint is handled by the right people, reducing delays and eliminating guesswork when every minute counts. These roles should be documented, tested, and updated as personnel or systems change.
- Assign a DR coordinator to oversee the end-to-end response.
- Define roles for backup, infrastructure, communication, and reporting.
- Clarify authority levels and escalation workflows.
- Document the team structure in DR runbooks.
- Conduct role-specific drills and training.
Communication Plan
Information spreads fast during a crisis, whether it’s accurate or not. A structured communication plan ensures that timely, verified updates are delivered to employees, clients, vendors, and leadership. This reduces confusion, preserves trust, and ensures alignment on recovery progress. Your plan should clearly define what to say, who says it, and when it’s said.
- Create templates for status updates, outage alerts, and recovery milestones.
- Define contact roles for technical leads, execs, and clients.
- Use multiple channels (email, phone, Teams, SMS).
- Establish an escalation protocol for major incidents.
- Store contact lists and instructions in cloud-accessible tools.
Data Backup and Storage
No disaster recovery plan is complete without a strategy for data backup and storage. Whether caused by ransomware or hardware failure, any data loss can cripple operations. Effective backup routines, secure storage locations, and verified restoration paths ensure that critical files and systems remain available, even under extreme failure scenarios.
- Identify and prioritize critical data for backup.
- Choose a mix of full, incremental, and differential backup types.
- Use both on-site and off-site/cloud backup repositories.
- Schedule automated backups and test restore reliability.
- Document backup cadence, storage locations, and retention policies.
Disaster Response Procedures
When disaster strikes, execution must be immediate and structured. Disaster response procedures provide a clear roadmap from the initial alert to complete system restoration. They include technical actions like system triage and restoration sequencing, and process steps like access control and team coordination, ensuring order during chaos.
- Define steps to trigger DR plan activation.
- Assess damage and scope of affected services.
- Restore systems in a prioritized sequence.
- Coordinate between technical and business teams.
- Complete integrity checks on restored systems.
Testing and Maintenance
Even the best-designed recovery plans degrade over time. Technology evolves, threats shift, and teams change. Testing and maintenance ensure your disaster recovery plan remains aligned with your infrastructure and organizational goals. Regular validation helps uncover blind spots and gives your team confidence through practice.
- Conduct simulation drills and tabletop exercises quarterly.
- Test full and partial failover procedures.
- Review DR logs, RTO/RPO adherence, and asset changes.
- Update documentation after each test cycle.
- Assign DR ownership and reporting roles for accountability.
Inventory of Assets
An accurate and regularly updated asset inventory allows teams to recover systems efficiently and completely. Without it, vital infrastructure may be overlooked in restoration efforts. Asset classification also helps align recovery workflows to business priorities and recovery objectives.
- Maintain a list of critical hardware, apps, and infrastructure.
- Tag assets with importance levels (e.g., Tier 1, Tier 2).
- Include dependencies like cloud apps or licensing keys.
- Track asset lifecycle and refresh schedules.
- Link the asset list with recovery objectives and SLA mapping.
Disaster Recovery Sites
Primary locations may become inaccessible in a disaster, due to fire, flood, or power outage. Disaster recovery sites (cold, warm, or hot) offer physical or cloud-based alternatives for restoring core operations. A reliable secondary site ensures minimal business disruption and faster recovery timelines.
- Choose an appropriate site type (cold, warm, or hot).
- Replicate critical systems and data to the recovery site.
- Establish secure connectivity and access controls.
- Verify system readiness with regular testing.
- Include site usage guidelines in the DR playbook.
Regulatory Compliance
Disasters don’t suspend regulatory requirements. From HIPAA to GDPR, your disaster recovery plan must ensure continuity in protecting sensitive data, maintaining audit trails, and fulfilling breach reporting obligations. Embedding compliance into the plan avoids legal risk during an already high-stress event.
- Identify relevant laws like HIPAA, GDPR, or PCI-DSS.
- Include compliance checkpoints in DR workflows.
- Maintain encrypted backups and access controls.
- Archive system logs and recovery steps for audits.
- Incorporate compliance testing into DR simulations.
What Is the Step-by-Step Process for Disaster Recovery?
The step-by-step process for disaster recovery is initiating the recovery process, assessing the damage, client, communication, backup & restore operations, system recovery, security response (if cyber incident), client access & validation, internal documentation, client notification & wrap-up, and debrief & improve. This recovery plan is designed to help prevent data loss, ensure sensitive data and SLAs remain compliant, and facilitate business continuity.
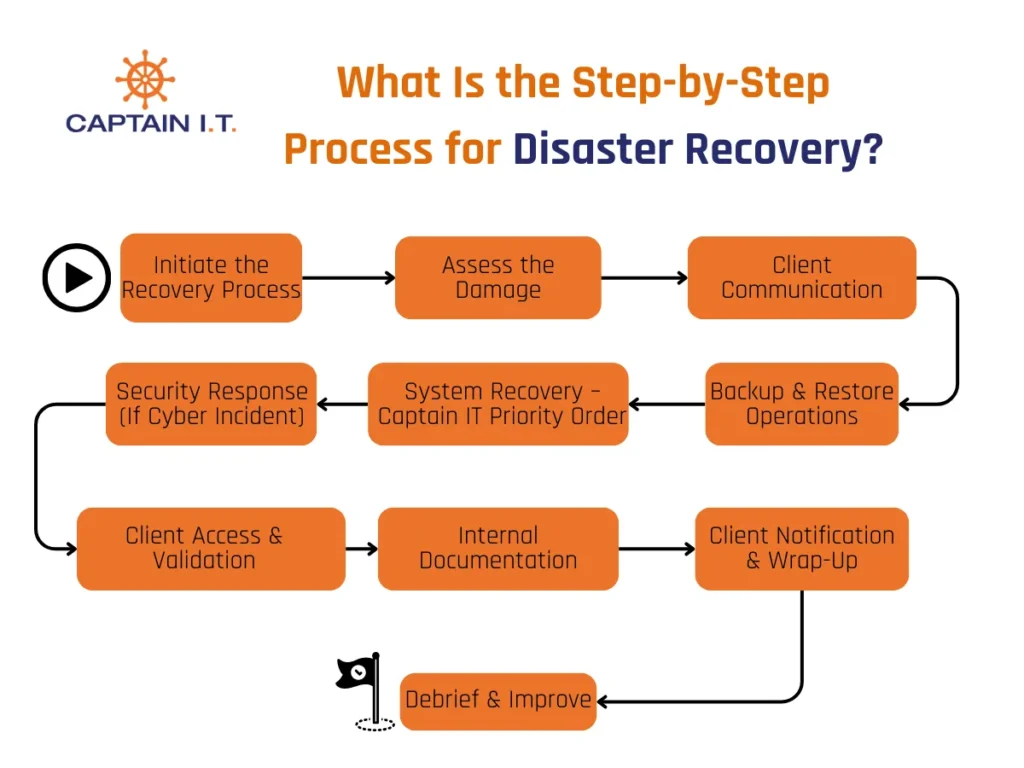
- Initiate the Recovery Process
Initiating the recovery process starts with triggering the disaster recovery plan, assessing the damage, and mobilizing the recovery team. This phase confirms that the companies respond efficiently and quickly.- Alert the Captain IT response team by creating an internal ticket and a Teams alert
- Notify the Account Manager and Client Primary Contact
- Classify the event, such as a cyberattack, a hardware failure, an outage, or a natural disaster
- Confirm if the client is on the Anchor, Compass, or Captain Plan
- Properly document the start time and who declared the event
- Assess the Damage
Identifying the scope and severity of the impact on data, systems, and operations helps businesses prioritize recovery actions and resource allocation while assessing the damage.- First, identify all affected systems like servers, internet, shared drives, etc
- Check and verify whether the remote users are impacted or not
- Review recent alerts from the firewall logs, RMM, and backups
- Contact the client to confirm what they’re experiencing
- Document scope and initial impact in the IT Glue ticket
- Client Communication
Client communication involves clear instructions, timely updates, and reassurance to clients about service restoration efforts to ensure trust and transparency during a crisis.- Clearly explain the issue, what is happening, and the expected timeframe
- Use the pre-approved disaster email or call script for communication
- Set expectations for hourly or milestone-based updates
- Reach out to our leadership if data loss, breaches, or extended outage is suspected
- Notify third-party vendors, like cloud apps and the internet, if they are involved
- Backup & Restore Operations
It is one of the vital steps in the disaster recovery process. Backup and restore operations ensure that critical data and systems are recovered quickly after a disruption.- Verify the previous successful backup
- Access backup systems like Axcient, client-specific, or Datto
- Restore data to a known-good state or an alternate location
- Perform a test restore before going for a full recovery
- Rebuild key systems such as file servers, DC, and QuickBooks if needed
- Log restore times and files restored in ticket notes
- System Recovery- Captain IT Priority Order
This step involves restoring services and IT systems after a disaster or failure to resume daily operations. It is a critical part of the recovery process, helping businesses reduce downtime and resume operations smoothly.- Domain controllers or Active Directory
- File Shares and QuickBooks
- Line of Business Applications
- Microsoft 365 or Exchange
- Internet Access & DNS
- VPN/ Remote Access
- Printers, scanners, or VoIP phones
- Endpoint reimaging if required
- Security Response (If Cyber Incident)
This focuses on identifying, containing, and eliminating cyber threats and ensuring business continuity by restricting damage and restoring affected systems securely.- Isolate systems that are compromised from the network
- Review FortiGate logs and SIEM, if they’re enabled
- Quickly reset passwords for affected accounts
- Scan endpoints with SentinelOne or your preferred EDR
- Coordinate with the external IR vendor if applicable
- Begin forensic logging and save relevant logs
- Client Access & Validation
It focuses on ensuring clients, whether internal users or external customers, can securely and fully access systems after recovery.- Verify whether staff can log in to restored systems
- Confirm that key business functions like accounting, email, and cloud apps are working
- Test printing, mapped drives, and remote desktop, if applicable
- Schedule post-recovery follow-up with the client
- Resume proactive monitoring and alerts
- Internal Documentation
It plays an important role in disaster recovery by capturing all necessary procedures, contacts, and protocols needed to restore services efficiently. Internal documentation also ensures that recovery actions are accessible, consistent, and aligned with organizational policies.- Update the ticket with a full timeline
- Attach screenshots, restore logs, and backup confirmations to IT Glue
- Document client-specific weaknesses or lessons
- Flag issues for Quarterly Business Review (QBR)
- Client Notification & Wrap-Up
The client notification & wrap-up stage ensures all clients and stakeholders are informed about the incident, recovery status, and any residual impacts to reinforce trust, closure, and transparency.- Send “All Systems Operational” update to clients and stakeholders
- Forward summary of what happened and how it was resolved
- Advise on any suggested changes, for example, implement MFA, add backup, upgrade firewall, and more
- Deactivate internal emergency mode
- Monitor all systems closely for the next 72 hours
- Debrief & Improve
It is the concluding phase of the disaster recovery process and focuses on analyzing the response and identifying areas for improvement once systems are restored and business operations resume. This step is to ensure that important lessons are learned and the disaster recovery plan evolves with each incident.- Hold an internal post-mortem meeting with the involved teams to review the recovery process
- Review the speed of response, restoration steps, and communication
- Update our playbooks, client configurations, and scripts
- Add the topic to the next team training or all-hands meeting
- Schedule a DR test or a tabletop for the affected client within 30 days
What Are The Best Practices for Disaster Recovery?
The best practice for disaster recovery is to develop a detailed plan, define RTO and RPO clearly, use off-site and cloud backups, automate backup processes, test the plan regularly, keep documentation up to date, establish clear roles, communicate effectively, and partner with reliable vendors. By ensuring that these practices are properly followed, DRP evolves to meet emerging threats and business changes.
- Develop a Detailed Plan
Creating a comprehensive and detailed recovery plan helps define roles and responsibilities, critical assets, recovery objectives (RTO/RPO), and step-by-step recovery procedures.
This ensures that every team member is familiar with what to do during a crisis, reducing confusion and boosting system restoration. - Define RTO and RPO Clearly
Recovery time objective (RTO) refers to the maximum acceptable amount of time a system, application, or process can be down after a disaster before causing a consequential impact.
Recovery point objective (RPO) is the maximum acceptable amount of data loss measured in time. For example, an RPO of 4 hours simply means that data must be backed up at least every four hours. - Use off-site and Cloud Backups
Stockpiling backups in off-site or cloud locations ensures that critical data remains accessible and safe when the primary site is compromised due to cyber attacks, system failures, or natural disasters. In addition, cloud backups offer automation, scalability, and quick recovery options, making them a reliable part of DRS. - Automate Backup Processes
Automating the backup process reduces the risk of human error and guarantees up-to-date copies of essential files and systems. This ensures that important data is regularly and consistently saved without relying on manual intervention.
You can schedule frequent backups, verify backup integrity, and store copies in multiple secure locations, on-site, off-site, or in the cloud. - Test the Plan Regularly
It identifies any potential breach before a real incident occurs and ensures its effectiveness. You can conduct scheduled drills, simulating different disaster scenarios, and involve all relevant team members for optimal results.
This method helps validate procedures, keep the recovery team well-prepared, and improve response time. - Keep Documentation Up to Date
Maintaining up-to-date documentation enables faster and more accurate recovery efforts and ensures all procedures, system configurations, contact information, and recovery steps align with the current IT environment.
Companies should schedule regular reviews, involve key stakeholders, and implement version control for documents to avoid confusion during emergencies. - Establish Clear Roles
Assigning clear roles and responsibilities ensures accountability and eliminates confusion during a crisis. Role-based drills and regular training help reinforce quick response and preparedness when each team member knows their specific tasks, like system checks, data restoration, or communication. - Communicate Effectively
Clear and timely communication is crucial, and establishing defined communication channels and assigning a spokesperson ensures that exact updates reach internal teams, customers, and stakeholders. Timely status reports and communication help reduce confusion and manage expectations throughout recovery. - Partner with Reliable Vendors
Collaborating with reliable vendors provides dependable backup services, cloud infrastructure, and technical support during a crisis. Businesses should ensure vendors meet their recovery time objectives and recovery point objectives through SLAs (Service Level Agreements). In addition, you can regularly review their performance and confused joint recovery tests to ensure readiness.
How Can You Ensure Business Continuity by Partnering with a Managed Service Provider?
Collaborating with a managed service provider is a strategic move to ensure business, especially during unexpected disruptions. It provides proactive monitoring, rapid response strategies, and data backups that keep your overall systems running with minimal downtime. Businesses or organizations can maintain operations, recover faster from cyber threats or outages, and safeguard data efficiently by leveraging their expertise.
And when it comes to reliable disaster recovery, our Captain IT team stands out as a go-to MSP. We specialize in tailored disaster recovery services that assist businesses in responding, preparing, and recovering from IT emergencies. We offer reliable data and system protection services and ensure your business is always prepared with regular testing, compliance support, and a well-integrated recovery plan.











